Multimodal scoring
Score every answer candidate using the original question, choices, and scientific figure.
Preprint · COLM 2026 Submission
1Korea University · 2Konkuk University · 3Myongji University · 4AIGEN Sciences
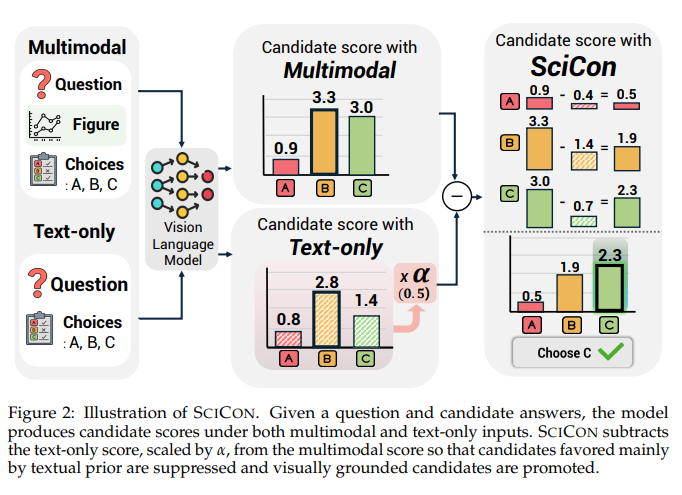
SCICON is a training-free contrastive decoding method for scientific figure multiple-choice QA. It subtracts each option's text-only preference from its image-conditioned score, suppressing answer choices that look scientifically plausible but are not grounded in the figure.
Problem
Scientific figure MCQA asks models to reason over charts, multipanel figures, microscopy, biomedical images, and symbolic diagrams. In this setting, the answer choices themselves often encode plausible hypotheses, trends, mechanisms, or experimental interpretations.
This creates choice-induced prior bias: a model may prefer an option because it sounds scientifically reasonable from the question and choices alone, even when the figure supports a different answer.
Method
For each candidate answer, SCICON compares the model's score with the figure against the score obtained after removing the figure. The final candidate score is computed as image-conditioned score - alpha x text-only score.
Score every answer candidate using the original question, choices, and scientific figure.
Remove the figure and score the same candidates again to expose option preference induced by text alone.
Subtract the text-only candidate score so choices favored mainly by textual plausibility are demoted.
Motivation
Preliminary experiments show that correct predictions move farther away from text-only preference, while wrong predictions remain more aligned with it.
Distance between multimodal and text-only answer distributions with Qwen3.5-4B.
| Dataset | JS Correct | JS Wrong | Cosine Correct | Cosine Wrong |
|---|---|---|---|---|
| MAC | 0.2477 | 0.1448 | 0.5559 | 0.7218 |
| SciFIBench | 0.1161 | 0.0728 | 0.7623 | 0.8253 |
| MMSci | 0.0870 | 0.0536 | 0.8005 | 0.8790 |
Results
SCICON improves accuracy across MAC, SciFIBench, and MMSci with Qwen3.5-4B, Qwen3.5-9B, Phi-3.5-vision-instruct, Llama-3.2-11B-Vision-Instruct, and Gemma-4-E4B-it.
Main scientific figure MCQA results. Values are ACC / macro-F1.
| Backbone | Method | MAC | SciFIBench | MMSci |
|---|---|---|---|---|
| Qwen3.5-4B | Greedy | 69.72 / 70.75 | 46.20 / 44.93 | 38.83 / 19.41 |
| VCD | 68.50 / 68.77 | 45.40 / 44.00 | 40.85 / 26.58 | |
| ICD | 58.41 / 58.57 | 40.50 / 38.23 | 33.79 / 14.83 | |
| SCICON | 74.01 / 74.24 | 48.70 / 46.99 | 43.44 / 19.06 | |
| Qwen3.5-9B | Greedy | 81.35 / 81.40 | 55.10 / 54.67 | 46.54 / 27.34 |
| VCD | 81.96 / 81.92 | 55.90 / 55.55 | 49.29 / 32.35 | |
| ICD | 81.04 / 81.01 | 53.00 / 52.13 | 46.65 / 24.14 | |
| SCICON | 82.26 / 82.34 | 58.00 / 57.55 | 52.14 / 33.91 | |
| Phi-3.5 | Greedy | 42.81 / 42.02 | 48.60 / 48.47 | 47.78 / 34.43 |
| VCD | 43.73 / 43.27 | 53.50 / 53.75 | 51.95 / 34.59 | |
| ICD | 42.81 / 41.60 | 47.10 / 46.86 | 46.32 / 31.38 | |
| SCICON | 49.54 / 49.89 | 54.90 / 55.02 | 52.71 / 29.93 | |
| Llama-3.2-11B | Greedy | 68.81 / 69.05 | 60.50 / 60.57 | 60.90 / 55.71 |
| VCD | 72.78 / 72.82 | 63.20 / 63.14 | 63.19 / 53.93 | |
| SCICON | 71.25 / 71.33 | 63.20 / 63.24 | 61.47 / 54.18 | |
| Gemma-4-E4B-it | Greedy | 66.97 / 67.04 | 53.50 / 53.19 | 59.28 / 53.89 |
| VCD | 68.81 / 68.80 | 48.00 / 48.15 | 56.18 / 46.93 | |
| SCICON | 66.97 / 67.17 | 56.40 / 55.83 | 64.11 / 59.17 |
Additional Evidence
Additional experiments show that prompt-only visual emphasis is inconsistent, adaptive prior subtraction is promising, and SCICON also improves MMBench.
Adaptive SCICON
SCICON-ada sets alpha from the similarity between image- conditioned and text-only answer distributions. This strengthens prior subtraction when the two distributions are highly aligned.
SCICON-ada results on Qwen3.5-9B. Values are ACC / F1.
| Dataset | Greedy | SCICON | SCICON-ada |
|---|---|---|---|
| MAC | 81.35 / 81.40 | 82.26 / 82.34 | 83.49 / 83.58 |
| SciFIBench | 55.10 / 54.67 | 58.00 / 57.55 | 58.80 / 58.58 |
| MMSci | 46.54 / 29.05 | 52.14 / 33.91 | 56.29 / 35.41 |
Broader MCQA
The same candidate-prior subtraction mechanism helps on MMBench even outside the scientific figure benchmarks, with consistent gains over greedy, VCD, and ICD across all three backbones.
MMBench results. Values are accuracy / macro-F1.
| Backbone | Greedy | VCD | ICD | SCICON |
|---|---|---|---|---|
| Qwen3.5-4B | 0.7438 / 0.7443 | 0.7535 / 0.7540 | 0.7048 / 0.7045 | 0.7616 / 0.7617 |
| Qwen3.5-9B | 0.7648 / 0.7643 | 0.7810 / 0.7809 | 0.7288 / 0.7284 | 0.7914 / 0.7908 |
| Phi-3.5 | 0.7923 / 0.7944 | 0.7976 / 0.7987 | 0.7789 / 0.7816 | 0.8018 / 0.8022 |
Analysis
Corrected cases show strong gold uplift and positive visual evidence margins. Harmed cases usually arise when the text-only prior already points to the correct answer, so subtracting it can remove useful signal.
Corrected cases show visual support for the gold answer.
| Dataset | Gold Uplift | Visual Margin |
|---|---|---|
| MAC | 1.568 | 2.088 |
| SciFIBench | 1.273 | 1.171 |
| MMSci | 1.301 | 1.197 |
Harmed cases often have a useful text-only prior.
| Dataset | Gold Hit | Harmed Alignment |
|---|---|---|
| MAC | 0.733 | 0.846 |
| SciFIBench | 0.739 | 0.887 |
| MMSci | 0.798 | 0.896 |
Takeaway
SCICON treats the answer options themselves as a measurable prior. By estimating that prior with a text-only pass and subtracting it, the method encourages models to choose answers supported by the scientific figure rather than by option plausibility.
The idea is intentionally lightweight: it requires no training and only one additional text-only scoring pass, making it a practical alternative to contrastive methods that require another full multimodal forward pass.
Resources
@article{roh2026choices,
title={When Choices Become Priors: Contrastive Decoding for Scientific Figure Multiple-Choice QA},
author={Roh, Taeyun and Jo, Eun-yeong and Jang, Wonjune and Kang, Jaewoo},
journal={arXiv preprint arXiv:2603.28026},
year={2026}
}